Data Analysis
In this section you will find a brief description of the Data Analysis Services being developed and provided to the PaN community.
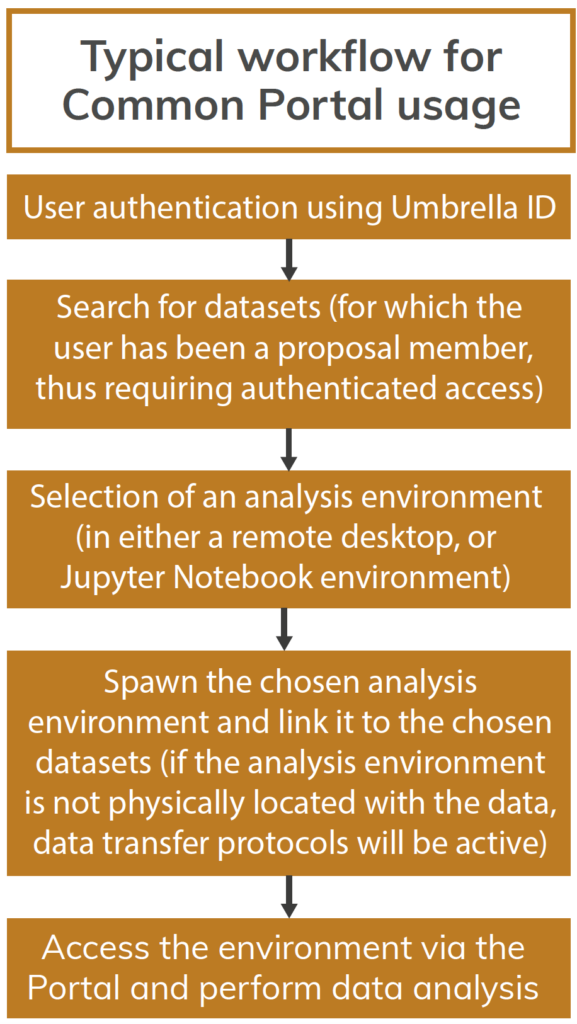
PaN portal for data analysis services
VISA, the Virtual Infrastructure for Scientific Analysis, enables to start a data analysis session as soon as a dataset has been collected. VISA provides access to both remote desktop environments and Jupyter Notebooks, enabling users to remotely analyse data from PaN facilities during or after the experiment.
Who is VISA for?
The VISA platform, by providing an integrated environment for analysing PaN related datasets based on popular tools like remote desktops and Jupyter notebooks, leverages the FAIR principles of the PaN data to enable scientists run analysis experiments. The environment offers support for real time collaboration through data sharing. It can have a possible impact on researchers of the PaN community, through increasing their scientific capacity and productivity.
VISA development
The development was based on enhancements to background work of ILL, based on the OpenStack open-source cloud platform. The federated instance of VISA was released in 2022, along with a cross-facility for searching for open data. The now closed PaNOSC project (2018-2022) contributed to the development of VISA.
A software package that facilitates High Performance Computing (HPC) centres was also implemented to install a scalable JupyterHub process for users. This boosts the inclusion of Jupyter notebooks in the portfolio of analytics services and tools of the project. Hence, PaN users can select between Jupyter notebooks and remote desktop solutions when it comes to analysing FAIR data via the PaN remote analysis services.
Source code for the portal can be found on github: https://github.com/panosc-portal
Watch the video on VISA
Jupyter Notebooks

PaNOSC has chosen the Jupyter Notebooks and Jupyter Lab from the Jupyter project as general purpose data analysis tool. Notebooks allow code and documentation to be intermingled in one document in the web browser. The uptake of the notebooks is proving to be very popular in data science partly because they support Python as programming language. A number of the scientific Use Cases for PaNOSC request solutions based on Jupyter notebooks. EGI provides a Jupyter notebook service for all PaN users with an UmbrellaId.

Binder is a service built on top of Jupyter notebooks to make scientific data analysis reproducible. EGI provides a Binder service for all PaN users with an UmbrellaId.
Remote Desktops
PaNOSC offers virtual machines for scientists to run applications which cannot be converted to Jupyter notebooks. The VMs are accessed through a remote desktop which exports the graphics to a browser. The PaN portal and its main back-end service VISA use Guacamole to export the desktop to a web browser. Extra features have been implemented to allow sharing of desktops between scientists.